DMA¶
PYNQ supports the AXI central DMA IP with the PYNQ DMA class. DMA can be used for high performance burst transfers between PS DRAM and the PL.
The DMA class supports simple mode only
Block Diagram¶
The DMA has an AXI lite control interface, and a read and write channel which consist of a AXI master port to access the memory location, and a stream port to connect to an IP.
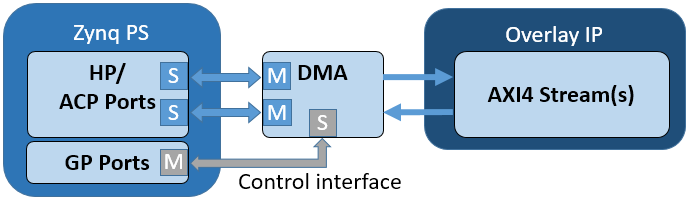
The read channel will read from PS DRAM, and write to a stream. The Write channel will read from a stream, and write back to PS DRAM.
Note that the DMA expects any streaming IP connected to the DMA (write channel) to set the AXI TLAST signal when the transaction is complete. If this is not set, the DMA will never complete the transaction. This is important when using HLS to generate the IP - the TLAST signal must be set in the C code.
Examples¶
This example assumes the overlay contains two AXI Direct Memory Access IP, one with a read channel from DRAM, and an AXI Master stream interface (for an output stream), and the other with a write channel to DRAM, and an AXI Slave stream interface (for an input stream). The two DMAs are connected in a loopback configuration through an AXI FIFO.
In the Python code, two DMA instances are created, one for sending data, and the other for receiving.
Two memory buffers, one for input, and the other for output are allocated.
import pynq.lib.dma
from pynq import Xlnk
import numpy as np
xlnk = Xlnk()
dma_send = ol.axi_dma_from_ps_to_pl
dma_recv = ol.axi_dma_from_pl_to_ps
input_buffer = xlnk.cma_array(shape=(5,), dtype=np.uint32)
output_buffer = xlnk.cma_array(shape=(5,), dtype=np.uint32)
Write some data to the array:
for i in range(5):
input_buffer[i] = i
Input buffer will contain: [0 1 2 3 4]
Transfer the input_buffer to the send DMA, and read back from the recv DMA to the output buffer. The wait() method ensures the DMA transactions have complete.
dma_send.sendchannel.transfer(input_buffer)
dma_recv.recvchannel.transfer(output_buffer)
dma_send.sendchannel.wait()
dma_recv.recvchannel.wait()
Output buffer will contain: [0 1 2 3 4]
More information about the DMA module can be found in the pynq.lib.dma Module sections